Advanced Analytics Architecture
Build modern data platforms using Microsoft Azure, Databricks, and Azure Data Factory. Transform raw data into actionable insights with Power BI for in-memory reporting and analytics.
Get Started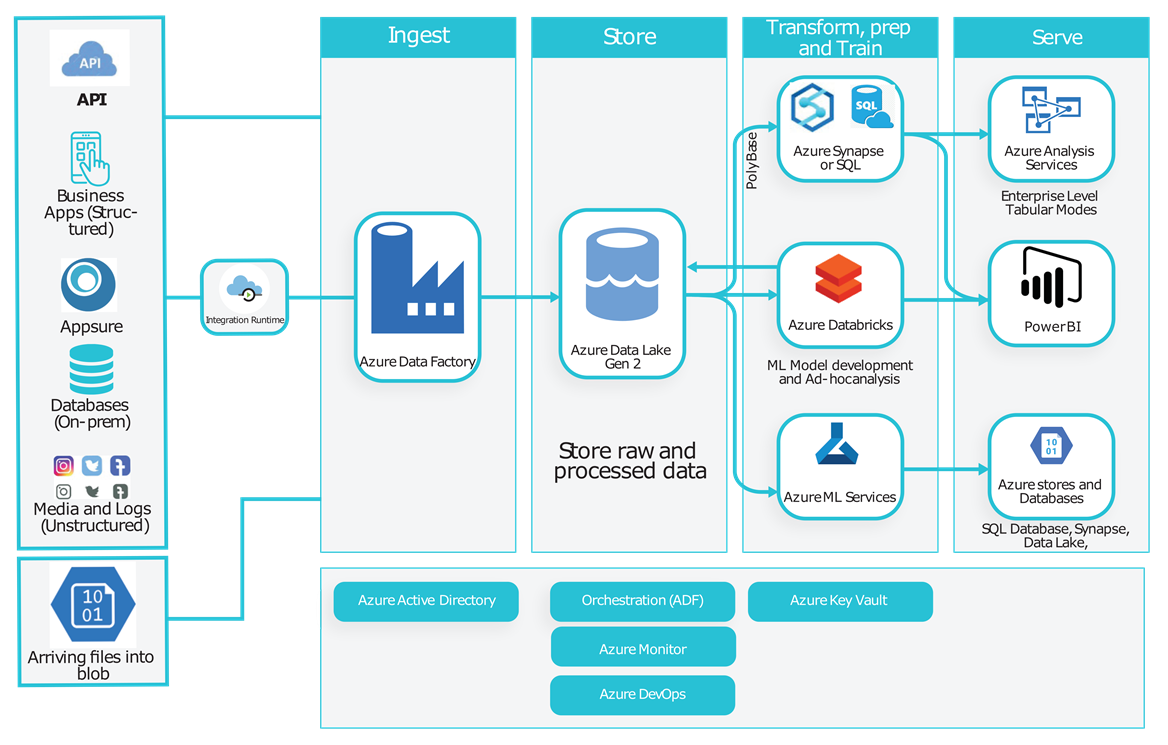
Data Platform Components
End-to-end data processing and analytics capabilities
1. Ingestion Process
Seamless data collection
Load data from various sources (structured or unstructured) and persist them in a central data lake storage. Supports multiple ingestion patterns for different data types and sources.
2. Store
Centralized data lake
Raw and processed datasets stored in Azure Data Lake with controlled access through Azure Active Directory. Maintains data lineage for auditing and regulatory compliance.
3. Processing
Prep and train
Azure Databricks as the main processing engine. Links to data lake storage, processes different data types, and prepares business-ready datasets with notification mechanisms.
4. Data Service Layer
Optimised data serving
Serves data via data lake and Azure SQL Data Warehouse. Azure Analysis Services provides enterprise-grade security, governance, and centralized metrics definitions.
5. Analytics & Reporting
Business intelligence
Power BI and Excel integration for self-service analytics. Real-time dashboards and reports with comprehensive security management and governance capabilities.
6. Machine Learning
Advanced analytics
Data scientists access datasets for Azure ML services or Databricks machine learning library. Supports predictive analytics and AI-driven insights.
Why Azure Databricks?
Apache Spark power as a service in Azure platform
Up to 100x Faster Processing
In-memory parallel processing system that runs significantly faster than traditional map-reduce jobs.
Spark SQL
Access data through familiar SQL-like commands for easy adoption and powerful querying capabilities.
Real-time Streaming
Support for real-time live streams of data with Spark Streaming for immediate insights.
Graph Processing
Comprehensive graph processing framework with GraphX for complex relationship analysis.
ML Library
Distributed machine learning framework for building and deploying AI models at scale.
DevOps Ready
Git integration, collaborative notebooks, and support for modern development practices.
Ready to unlock the power of your data?
Let's build a modern data platform that drives insights and innovation